搜索引擎的工作原理是什么?它是如何处理信息的?
 游客
2025-03-22 08:22:01
10
游客
2025-03-22 08:22:01
10
在互联网信息爆炸的时代,搜索引擎成为了人们获取知识和信息的主要工具之一。我们每天都在使用搜索引擎,但你是否了解搜索引擎的工作原理呢?本文将带你深度解析搜索引擎是如何处理信息的。
搜索引擎的基本工作流程
搜索引擎的工作流程大体可以分为三个阶段:爬取、索引和检索。
爬取:搜索引擎的“侦察兵”
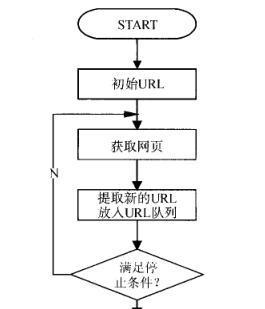
爬取(Crawling)是搜索引擎获取网页信息的第一步。就好比侦察兵在战场上收集情报,搜索引擎的爬虫程序(也称为蜘蛛或机器人)在互联网上不断访问各个网站,并按照一定的算法——通常是优先获取重要页面或者频繁更新的页面——进行网页内容的下载和存储。这个过程中,爬虫会遵循网页中的链接不断深入访问新的内容,进而形成一个覆盖互联网大部分页面的数据库。
索引:搜索引擎的“图书馆”
当爬虫收集到网页后,接下来的步骤就是索引(Indexing)。在这一阶段,搜索引擎要处理和分析爬虫获取来的大量数据,并决定哪些内容是有价值并应该被存储的。搜索引擎会分析网页的标题、文本内容、图片、视频等多媒体信息,并将其分类存储在索引库中。索引库就像一个巨大的图书馆,方便用户在检索时能快速找到所需的书籍(即网页信息)。
检索:搜索引擎的“信息搜索者”
最后是检索(Retrieval),这也是用户直接体验到的部分。用户输入关键词进行查询时,搜索引擎会在索引库中快速查找相关的网页,并根据一定的排名算法计算出一个结果列表展示给用户。这个过程中,搜索引擎需要考虑到网页的相关性、权威性、及时性等多个因素。

如何进行网页的爬取与索引
网页爬取的策略
对于爬取过程而言,搜索引擎采用不同的策略以优化其效率和效果。比如:
深度优先:搜索引擎的爬虫从一个网页开始,按照链接深入爬取下去,直到达到设定的深度或条件。
广度优先:从一个网页开始,先爬取该网页的所有链接,然后对每一个链接页面进行相同的处理。
除此之外,搜索引擎的爬虫还需要处理各种网络上的陷阱,比如重复内容、死链接、跨站请求伪造等问题。
对网页内容的索引
在索引阶段,搜索引擎会进行更为复杂的处理:
内容提取:去除无用的元素,如HTML标签、脚本等,提取出网页中的纯净文本内容。
语义分析:理解文本内容的含义,包括关键词提取、意图识别等。
结构化数据:抽取网页中的结构化信息,如地址、电话等,方便用户查询时提供直接答案。
页面排重:对于内容相似的页面进行识别和合并,避免信息冗余。

搜索结果的排名机制
当用户输入查询关键词后,搜索引擎的检索过程会迅速启动。这个阶段涉及的核心是算法,这些算法会综合考虑页面的相关性、用户体验、网站的权威度等多个因素,最终呈现出一个排序后的搜索结果列表。这里需要强调的是,不同的搜索引擎会有其独特的算法,但通常都会包括以下几个方面:
关键词匹配:检索用户查询的关键词在哪些页面中出现过。
页面质量评估:分析页面的权威性和可信度,包括外链数量和质量、域名的历史和权威性。
用户行为分析:用户在搜索结果中的点击行为、停留时间等指标。
个性化搜索:考虑用户的搜索历史、地理位置等个性化因素。

优化搜索体验的策略和挑战
为了向用户提供更佳的搜索体验,搜索引擎不断优化和更新其算法。“移动优先”的策略、人工智能技术的应用、对伪原创内容的严格把控等。同时,搜索引擎还面临着诸多挑战,如如何处理垃圾信息、如何保证搜索结果的实时性和准确性、如何解决数据隐私和安全问题等。
结语
通过以上详尽的解析,我们了解到搜索引擎的确是一个复杂而精密的系统。它不仅仅是技术的体,更是处理和管理海量互联网信息的智能工具。随着技术的进步,搜索引擎会变得更加智能化、人性化,为用户提供更加高效、准确的搜索结果。掌握其工作原理能帮助我们更好地利用搜索引擎,提升我们的信息获取效率。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3561739510@qq.com 举报,一经查实,本站将立刻删除。
转载请注明来自星舰SEO,本文标题:《搜索引擎的工作原理是什么?它是如何处理信息的?》
标签:搜索引擎
- 上一篇: 小红书数据分析有哪些技巧?
- 下一篇: 哔哩哔哩缓存视频文件夹在哪里?



- 搜索
- 最新文章
- 热门tag
- 热门文章
-
- 深圳seo关键词优化有哪些技巧?如何选择专业的优化公司?
- 合肥网站制作的流程是什么?如何确保网站质量?
- 个人网站建设有哪些难点?如何解决个人网站建设中的常见问题?
- 网站建设与优化的步骤是什么?如何提升网站的搜索引擎排名?
- 搜索引擎关键词优化的方法是什么?
- 北京seo公司有哪些?如何选择本地的优化服务?
- 企业网站建设设计有哪些要点?如何提升企业形象?
- 百度seo优化工具如何帮助网站提升流量?
- 免费网站设计真的可靠吗?有哪些陷阱需要注意?
- 目前素材网站排行榜上有哪些网站?它们各自有什么特点?
- 如何进行网络推广网站?推广中常见问题有哪些?
- 小红书seo怎么做?如何提高在小红书的搜索排名?
- 如何在国外进行网站推广?有哪些有效的推广策略?
- 无锡关键词优化有哪些特点?
- 百度seo排名优化如何进行?
- ae素材网站哪里找?如何选择合适的ae素材网站?
- 关键词工具如何使用?如何帮助SEO优化?
- 天津网站制作公司有哪些?如何确保网站制作质量?
- 高端网站建设需要多少钱?如何选择合适的建站公司?
- 郑州seo优化需要多久见效?优化策略是什么?
